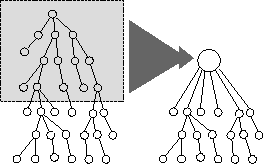
Nous reprenons ici les concepts expliqués en 5 en les abordant sous un angle plus technique.
Plus précisément, nous décrirons les algorithmes mis en ![]() uvre pour manipuler l'arbre d'évaluation.
Les critères d'arrêt de précision et de visibilité feront l'objet d'une attention particulière.
uvre pour manipuler l'arbre d'évaluation.
Les critères d'arrêt de précision et de visibilité feront l'objet d'une attention particulière.
La structure de ce chapitre est la suivante :
Nous verrons dans cette section les mécanismes complexes mis en ![]() uvre durant la génération de l'arbre d'évaluation.
Nous verrons ensuite comment Dynamic Graph assure une certaine connaissance des informations anciennes, notamment grâce à l'utilisation d'identifieurs.
Nous décrirons enfin l'arbre permanent qui, contrairement à un arbre d'évaluation, contient des informations permanentes.
Enfin, nous dresserons un bilan de la méthode d'évaluation et proposerons deux améliorations potentielles.
uvre durant la génération de l'arbre d'évaluation.
Nous verrons ensuite comment Dynamic Graph assure une certaine connaissance des informations anciennes, notamment grâce à l'utilisation d'identifieurs.
Nous décrirons enfin l'arbre permanent qui, contrairement à un arbre d'évaluation, contient des informations permanentes.
Enfin, nous dresserons un bilan de la méthode d'évaluation et proposerons deux améliorations potentielles.
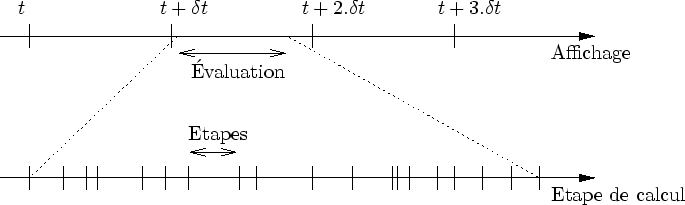
La génération de l'arbre d'évaluation est dirigée par l'organiseur, via un visiteur particulier : le générateur. L'évaluation d'un amplifieur est réalisée de façon séquentielle : elle ne se termine qu'après plusieurs phases d'exécution. Pour permettre cela, un dialogue a lieu entre le générateur et un amplifieur : le générateur donne des requêtes auxquelles l'amplifieur essaie de répondre.
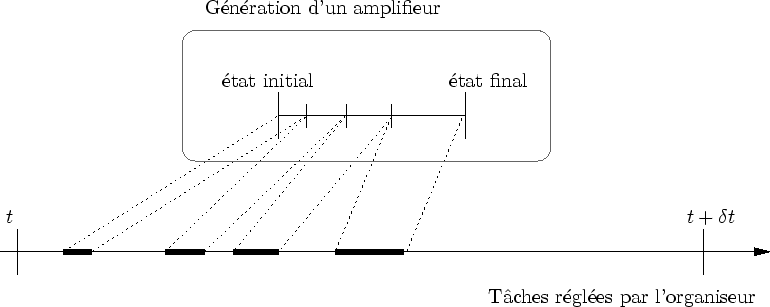
À chaque pas de temps, l'évaluation de la forme est effectuée par la création d'un arbre d'évaluation. La création de cet arbre est rythmée par l'organiseur. D'emblée, on distingue deux sortes d'événements temporels (cf. figure 6.1):
 |
Le générateur est le visiteur qui s'occupe de ``développer'' l'arbre d'évaluation jusqu'à sa complexion. On peut voir un visiteur est une entité qui se déplace sur un graphe pour appliquer un traitement à chaque noeud. Mais dans Dynamic Graph, il est plus intuitif de voir le phénomène ``dual'' : ce sont les noeuds du graphe qui vont visiter le visiteur (cf. figure 6.2).
Cette différence est importante pour décrire l'évaluation avec une architecture en pipe-line. Plutôt que de visualiser un arbre dont les noeuds ne bougent pas, il est préférable d'imaginer qu'un amplifieur, lors de son traitement, entame un sorte de pèlerinage qui le mènera éventuellement à la carte graphique.
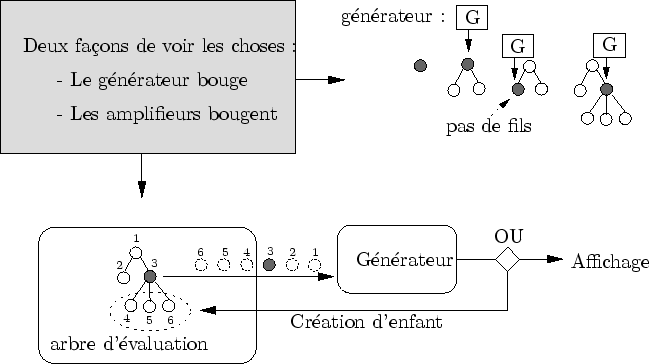 |
Comme on l'a vu, un amplifieur, lorsqu'il est évalué, ajoute de la précision à la forme. L'organiseur s'occupe de lancer le calcul des amplifieurs via le visiteur générateur. Afin de bien contrôler l'évaluation, l'organiseur reprend la main entre deux évaluations. Ceci est essentiel pour assurer un certain parallélisme entre le processeur central et la carte graphique (nous verrons en section 6.3 pourquoi un tel parallélisme est nécessaire).
Comme toute action sur un ordinateur, l'évaluation d'un amplifieur n'est pas instantanée et il faut un certain nombre de cycles d'horloge pour que le processeur la termine. Lorsqu'un amplifieur est construit, il est dans son état initial : seule l'initialisation de l'évaluation a lieu. Lorsque l'évaluation est terminée, l'amplifieur est dans son état final : il a terminé tous ses calculs.
 |
Cette évaluation séquentielle est mise en ![]() uvre pour permettre à un amplifieur d'attendre la fin de tâches parallèles sans bloquer le processeur courant.
En effet, imaginons que l'évaluation d'un amplifieur requiert une certaine information qui n'est pas encore prête : l'amplifieur devient alors bloquant.
Plutôt que d'attendre inutilement, l'amplifieur peut rendre la main à l'organiseur qui va aller ``stimuler'' d'autres amplifieurs non-bloquants.
uvre pour permettre à un amplifieur d'attendre la fin de tâches parallèles sans bloquer le processeur courant.
En effet, imaginons que l'évaluation d'un amplifieur requiert une certaine information qui n'est pas encore prête : l'amplifieur devient alors bloquant.
Plutôt que d'attendre inutilement, l'amplifieur peut rendre la main à l'organiseur qui va aller ``stimuler'' d'autres amplifieurs non-bloquants.
En théorie, Dynamic Graph est donc parfaitement conçu pour tourner en parallèle sur plusieurs processeurs. Pourtant, ce n'est pas ce type de parallélisme qui est visé en premier. Les évaluations séquentielles sont initialement prévues pour assurer une bonne synchronisation entre le processeur principal et le processeur graphique (cf. section 6.3).
Les amplifieurs bloquants sont référencés dans une liste appelée la salle d'attente (cf. figure 6.4). Elle réinjecte les amplifieurs qui se sont débloqués vers le générateur. Une priorité est attribuée aux amplifieurs débloqués afin de libérer plus vite d'autres amplifieurs.
Si tous les amplifieurs sont bloquants, l'organiseur attend. Il est donc, par exemple, plus important de libérer un amplifieur dont on estime que les enfants sont nombreux. En effet, tout nouvel amplifieur est par défaut non bloquant. Plus le nombre d'amplifieurs non-bloquants est grand, plus l'organiseur peut organiser son travail efficacement. Remarquez que ce mécanisme permet de diminuer les durée de blocage, mais non de les supprimer.
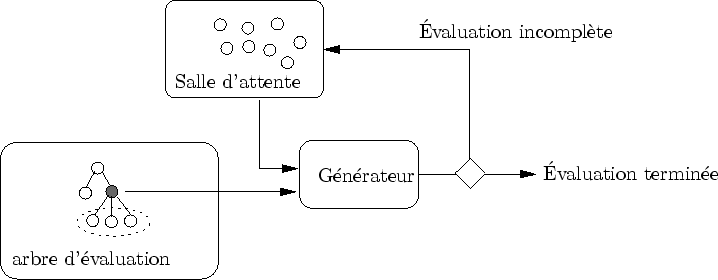 |
On peut formaliser l'échange complexe qui a lieu entre un visiteur et un amplifieur de la façon suivante : pour déclencher l'évaluation d'un amplifieur, le visiteur lance une requête. Lorsque l'amplifieur lui rend la main, le visiteur vérifie si la requête est satisfaite. Dans le cas contraire, il envoie cet amplifieur dans la salle d'attente.
Différentes sortes de requêtes sont possibles. La plus courante est la requête de complexion : "Dessine la forme ou génère des enfants si nécessaire". D'autres requêtes sont possibles. Par exemple, le générateur peut forcer certains calculs : "génère tes enfants quoiqu'il arrive".
On peut représenter les différentes fonctions qu'un amplifieur peut réaliser par un graphe de dépendance des résultats qu'il peut produire (cf. figure 6.5). Au cours d'une même observation, l'amplifieur se souvient des fonctions qu'il a déjà exécutées. De cette façon, lors d'une reprise des calculs, l'évaluation peut reprendre là où elle s'était arrêtée.
 |
Généralement, le générateur demande la requête de complexion à tous les amplifieurs. La complexion d'un amplifieur entraîne souvent la création de nouveaux amplifieurs qui doivent être évalués à leur tour. Lorsque tous les amplifieurs satisfont la requête de complexion, l'évaluation est terminée.
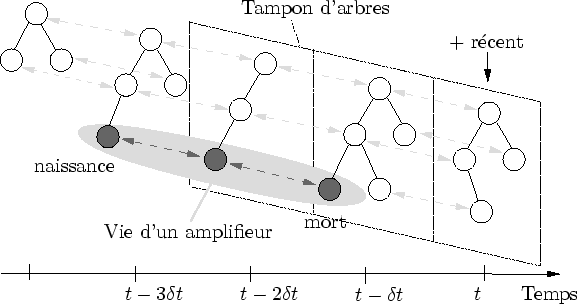
Dans Dynamic Graph, chaque arbre d'évaluation connaît son ancêtre (notamment pour permettre l'optimisation par cohérence temporelle). Ceci est réalisé grâce au tampon d'arbres et aux identifiants attribués à chaque noeud. Chaque amplifieur a une date de naissance et de mort définissant sa durée de vie, notamment utilisée pour stocker des informations sur une longue durée.
Le tampon d'arbres stocke les ![]() derniers arbres d'évaluations.
derniers arbres d'évaluations.
![]() est fixé par le créateur ou l'application, selon les besoins de l'un ou de l'autre.
Cette valeur peut être modifiée dynamiquement durant l'exécution du programme.
est fixé par le créateur ou l'application, selon les besoins de l'un ou de l'autre.
Cette valeur peut être modifiée dynamiquement durant l'exécution du programme.
Son implémentation est basé sur l'utilisation de ``tableaux rotatifs''.
Ces tableaux sont tout simplement des tableaux normaux dont l'accès est rendu cyclique en prenant les index modulo ![]() .
.
Lorsque le programme débute, les premières cases du tableau, initialement vides, sont successivement remplies par un arbre d'évaluation. Lorsque le tableau est plein, les cases les plus vieilles sont libérées pour laisser place aux nouveaux arbres.
Chaque arbre d'évaluation est connecté à son ancêtre (l'arbre du pas de temps précédent). La connexion est réalisée dans les deux sens, ce qui signifie que chaque arbre est connecté à son ancêtre et à son successeur (s'ils existent).
 |
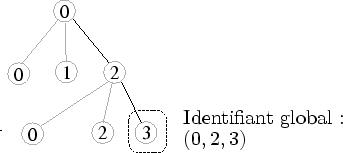
Lorsque l'on dit qu'un arbre est connecté à son ancêtre, cela signifie que chacun de ses noeuds (i.e. amplifieurs) est connecté à son noeud ancêtre (cf. figure 6.6). Cette connexion est réalisée durant la création d'un nouvel arbre (c'est-à-dire durant une nouvelle évaluation). Le principe est simple : chaque noeud a un identifiant global le distinguant de tous les autres noeuds d'un même arbre. Lorsqu'un noeud est créé, il vérifie si un noeud du même identifiant existe dans l'arbre précédent : s'il existe, la connexion est créée. Ceci baigne chaque amplifieur dans une structure de liste doublement chaînée.
Une recherche d'identifiant global dans un arbre est une opération dont le coût n'est pas négligeable. Si l'on considère que l'accès à un fils est réalisé en coût constant, le coût moyen d'une recherche est proportionnel à la hauteur de l'arbre précédent. La réaliser lors de la création de chaque nouveau noeud grèverait considérablement les performances. L'utilisation d'identifiant local permet de palier ce problème.
Un identifiant local permet de distinguer un amplifieur parmi ces frères.
Concrètement, un identifiant local est un entier non signé.
Un identifiant global est une liste d'identifiants locaux décrivant le chemin à suivre pour aboutir au noeud en question (cf. figure 6.7).
Chaque noeud de l'arbre contient un conteneur vers ces noeuds fils.
Ce conteneur est un conteneur associatif [D'A02] dont la clef (unique) est l'identifiant local.
Accéder au fils
![]() revient donc à chercher l'existence de cette clef dans le conteneur associatif.
revient donc à chercher l'existence de cette clef dans le conteneur associatif.
 |
Pour les raisons de performance identifiées plus haut, les identifiants locaux sont utilisés pour faire des recherches relatives. Pour comprendre intuitivement le mécanisme, on peut le comparer aux chemins de fichiers sous UNIX. Il est en effet souvent plus efficace d'accéder à un fichier par un chemin relatif comme :
"../source/toto.cpp"
que par un chemin absolu comme :
"/home/evasion/perbet/cpp/dg/model/source/toto.cpp"
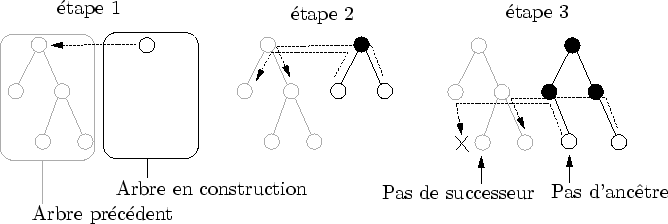
La recherche de l'ancêtre est réalisée au cours de l'évaluation. Elle est initialisée avec la racine du nouvel arbre : celui-ci est spécifiquement connecté à la racine de l'arbre précédent par l'organiseur. Ensuite, chaque nouvel amplifieur a pour ancêtre (au sens temporel) "le fils de l'ancêtre de son père" (cf. figure 6.8). Comme les connexions sont réalisées au fur et à mesure, on est assuré que le père d'un amplifieur connaît déjà son ancêtre.
 |
À chaque pas de temps, lorsque le tampon d'arbres est plein, l'arbre le plus vieux est détruit. C'est un visiteur particulier qui s'occupe de ça : le destructeur. Celui-ci parcourt l'arbre des feuilles vers la racine en utilisant le retour d'un parcours en profondeur d'abord.
Il détruit tous les fils de l'amplifieur qu'il visite (la racine a un traitement particulier). De plus, si l'amplifieur n'a pas de successeur, il appelle sa fonction de mort. Si l'amplifieur à un successeur, il supprime proprement ce lien (dans les deux sens).
La figure 6.6 montre la vie et la mort d'un amplifieur. La naissance est par définition une construction sans ancêtre et la mort une destruction sans successeur. Lors de la naissance (resp. de la mort) d'un amplifieur, un constructeur (resp. un destructeur) spécial est appelé.
Cette fonctionnalité permet d'initialiser de l'amplifieur.
Par exemple, une texture peut être allouée lors de la naissance et désallouée lors de la mort.
Plus généralement, la naissance et la vie d'un amplifieur permet de stocker n'importe quelle information mortelle pendant plusieurs pas de temps.
L'information mortelle dure plus longtemps que les informations éphémères qui sont stockées dans un amplifieur : celles-ci sont accessibles ![]() pas de temps ou
pas de temps ou ![]() est la taille du tampon d'arbres
En revanche, l'information mortelle dure moins longtemps que l'information permanente qui est décrite dans la sous-section suivante.
est la taille du tampon d'arbres
En revanche, l'information mortelle dure moins longtemps que l'information permanente qui est décrite dans la sous-section suivante.
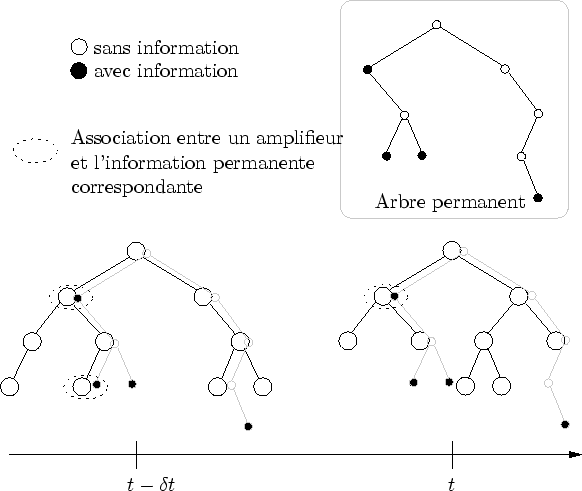
Les arbres d'évaluation, très dynamiques, sont complétés par un arbre permanent, représentant en quelque sorte la partie statique de l'évaluation. Il sert à stocker toutes les informations qui ne sont pas animés et ne nécessitent donc pas d'être recalculer à chaque pas de temps. Cet arbre ne dépend pas de l'observation et peut donc être très grand ; en conséquence, un effort particulier est fait pour maintenir sa taille la plus petite possible.
Les informations stockées dans les noeuds sont très volatiles : leur durée de vie est celle de la taille du tampon d'arbres. Afin de donner la possibilité de stocker des informations de façon permanente, un arbre statique complète le tampon d'arbres dynamiques. Dans le cas de la prairie, par exemple, la courbure et la direction d'un brin d'herbe sont stockées dans l'arbre dynamique, alors que la couleur du brin d'herbe est stockée dans l'arbre permanent. Il permet d'associer à des amplifieurs particuliers des données supplémentaires. Il est appelé l'arbre permanent.
Les noeuds qui le composent, parce qu'ils représentent la partie permanente de l'information, sont appelés amplifieurs permanents. On peut représenter cet arbre comme un arbre partiellement superposable aux arbres d'évaluations mais beaucoup moins dense que ceux-ci (cf. figure 6.9).
 |
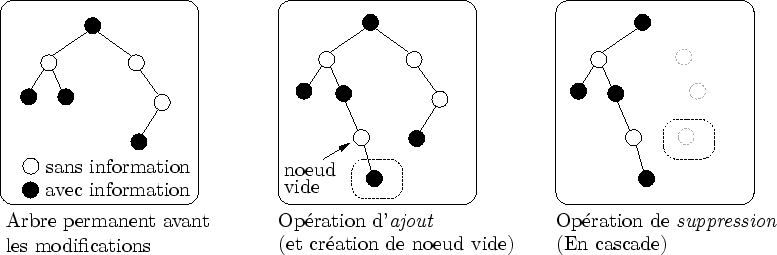
Rappelons que l'arbre d'évaluation est potentiellement infini. Seuls les critères d'arrêt qu'engendre une observation permet de limiter son expansion. L'arbre permanent n'est a priori pas sujet à cette restriction : les informations qu'il contient sont permanentes, que l'amplifieur soit observé ou non. Elles ne peuvent être supprimées que par une intervention explicite (soit du créateur, soit de l'organiseur).
Si chaque amplifieur demande un homologue dans l'arbre permanent, la taille de celui-ci explose. Son utilisation doit donc rester exceptionnelle : seul quelques amplifieurs spéciaux peuvent l'utiliser.
De plus, afin de minimiser la mémoire occupée par l'arbre permanent, il est nécessaire de garder sa taille la plus petite possible. Pour cela, on s'assure que ce dernier est le plus petit graphe contenant tous les amplifieurs permanents (cf. figure 6.10). Concrètement, cela évite de garder en mémoire des informations concernant une forêt dans une zone désertique.
 |
Lorsqu'un visiteur parcourt l'arbre d'évaluation, il parcourt en même temps l'arbre permanent. Ainsi, lorsqu'un amplifieur s'apprête à être visité par le générateur, il est enrichi d'une référence vers ses éventuelles informations permanentes (cf. figure 6.11).
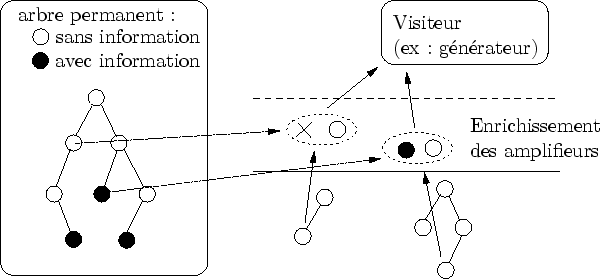 |
Lors de l'évaluation de l'amplifieur, le générateur met à disposition de celui-ci la zone de mémoire permanente. Elle est utilisée pour stocker des informations importantes. Dans un jeu, par exemple, cette mémoire peut servir à se souvenir qu'un objet particulier a été déposé ici par le joueur.
La structure dynamique de Dynamic Graph permet de représenter des structures en perpétuelles transformations, parfaitement adéquate à une représentation par complexification. Néanmoins, on est en droit de se demander si cette structure n'est pas trop dynamique. Une nouvelle conception du tampon d'arbres local semblerait apporter une réponse. Enfin, nous verrons que le parcours de l'arbre d'évaluation dépend de l'échelle d'observation et limite ainsi les zooms très grands ; nous verrons comment la méthode de congélation, apporterait une solution partielle.
La complexification entraîne une vision très dynamique de la forme affichée : celle-ci, en plus de son animation, s'adapte sans cesse aux mouvements de l'observateur. Pour représenter une forme aussi mouvante, il est nécessaire d'utiliser une structure qu'il est facile de mettre à jour. Dynamic Graph choisit une solution extrême : à chaque pas de temps, tout est régénéré. C'est un pari risqué : tout sur la génération à la volée.
La souplesse de la structure choisie est un avantage. La conception d'un algorithme traitant de scènes statiques a souvent quelques difficultés lorsqu'il faut passer à l'animation6.1. Dynamic Graph prend le parti inverse : la conception est entièrement pensée pour des structures animées. Lors de la modélisation de structure statique avec Dynamic Graph, il est toujours possible d'utiliser l'optimisation par cohérence temporelle. Nous verrons dans le chapitre 7 comment les informations éphémères, mortelles et permanentes peuvent être utilisée pour cela.
On peut tout de même reprocher à Dynamic Graph de faire beaucoup de calculs inutils lors de la modélisation de scènes statiques. Notamment, il devient inutile d'assurer la liaison entre un ancêtre et son successeur. Dynamic Graph propose généralement plus que ce que désire le créateur : c'est une façon d'être sûr que ce dernier ne se sente pas limité. En revanche, cela entraîne un coût supérieur à l'approche classiquement utilisée : la modification d'une structure statique.
Il est très délicat d'argumenter de façon générale des avantages et des inconvénients d'une structure statique (modifiée) ou d'une structure dynamique (générée à la volée). Ceci dépend notamment des fonctions que code le créateur au sein d'un générateur d'amplifieurs : certaines supportent très bien les modifications, d'autres moins. Dynamic Graph permet suffisamment de souplesse (grâce aux informations mortelles et permanentes) pour laisser le choix au créateur. Néanmoins, le comportement par défaut est celui de la régénération.
La modification est souvent plus efficace que la régénération lorsqu'il existe une forte similarité entre deux images (i.e. observation). Cette contrainte n'est pas toujours assurée. Même si l'observateur évolue très souvent de façon continue, il arrive fréquemment qu'il se déplace trop vite et que les opérations de modification deviennent ainsi trop coûteuses. La régénération est plus souple à ce niveau et permet généralement des mouvements de caméra moins contraints.
L'une des plus grandes limites de l'algorithme actuel est l'impossibilité d'assigner des fréquences de mise à jour différentes pour chaque générateur d'amplifieurs. Une telle fonctionnalité est similaire à celle de la plateforme de simulation OpenMask [Mar02] ou aux MTG [GC98]. Elle permettrait par exemple d'insérer des objets statiques avec une fréquence de mise à jour nulle. Une telle structure semble réalisable grâce à une conception plus locale du tampon d'arbres (cf. figure 6.12).
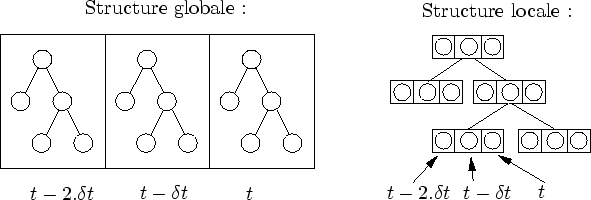 |
Cette conception est à vrai dire très séduisante. Elle permettrait aux visiteurs d'ignorer les noeuds n'ayant pas besoin de mise à jour. De plus, la recherche de l'ancêtre serait alors immédiate. Il serait très intéressant de coder cette solution et de la confronter à l'implémentation actuelle.
La régénération à chaque pas de temps de tout l'arbre d'évaluation entraîne un coût qui dépend de l'échelle d'observation : plus la scène est précise, plus l'arbre est grand et plus le temps de parcours augmente.
Même si l'arbre à son niveau grossier est très mince, il faut au moins parcourir toute la hauteur.
Ceci pose problème pour les très grandes variations d'échelle.
En fait, nous n'avons pas pu observer ce phénomène car nous avons été limités par les problèmes d'imprécisions numériques.
En effet, lorsque la caméra se rapproche trop d'un objet, la taille des détails observés et trop petite pour être représenté sur nombre constant de bits (typiquement ![]() ou
ou ![]() ).
).
Ce n'est pas parce qu'un problème est caché par un autre que l'on peut l'ignorer, voyons les solutions qui s'offrent à nous. On peut envisager de congeler la partie grossière de l'arbre en une sorte ``d'amplifieur axiome compressé'' (cf. figure 6.13). Ce dernier pourrait, par exemple, représenter la partie congelée (forcément très lointaine) par un imposteur. Mais alors, l'animation des parties grossières du graphe seront ignorées. Cette approche ne pose pas de problème pour les zooms ``allé simple'' ou l'observateur se rapproche sans cesse sans jamais reculer beaucoup.
On peut imaginer que les générateurs d'amplifieurs sachent non seulement ajouter de la précision en créant des amplifieurs fils, mais aussi enlever de la précision en créant leur amplifieur père6.2. On touche ici à la limite intrinsèque de la complexification : celle-ci ajoute de l'information mais ne sait pas en enlever. Les langages descriptifs simples utilisés dans les méthodes de simplification autorisent la diminution de la précision. Mais dans le cas du langage descriptif complexe de Dynamic Graph, je vois mal comment une telle prouesse peut être réalisée...
La fin de ce chapitre est dédié aux critères d'arrêt de la génération de l'arbre d'évaluation de Dynamic Graph: la précision et la visibilité. Dans cette section, la précision sera définie. Ensuite, nous ferons une première incursion du côté de la modélisation et nous présenterons la maturité comme une transformation pratique de la précision. Enfin, nous conclurons sur ces deux concepts avant de passer au second critère d'arrêt : la visibilité
Nous définirons tout d'abord la précision de manière formelle. Nous la reformulerons ensuite de façon approximative, efficace et suffisante aux besoins de Dynamic Graph. Nous verrons enfin comment la précision intervient lors de la génération de l'arbre d'évaluation.
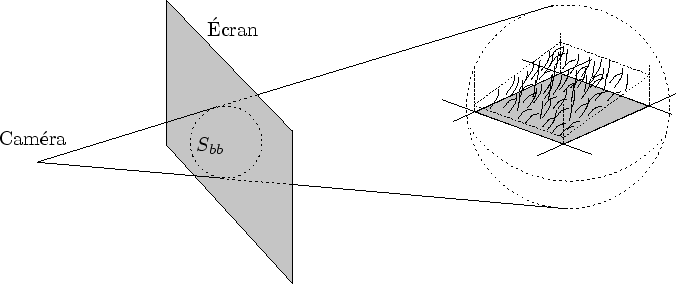
La précision est une notion très délicate à définir. Nous avons vu en 2.1 qu'un signal pouvait être sur-échantillonné ou bien sous-échantillonné. Dans Dynamic Graph, la précision est représentée par un nombre réel mesurant la qualité de l'échantillonnage (cf. figure 6.14).
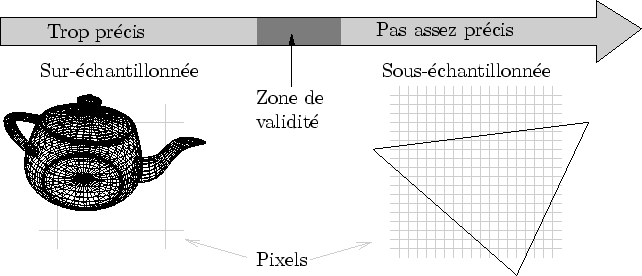 |
Plus formellement, on peut considérer qu'un amplifieur ![]() affiché envoie un ensemble de primitives graphiques :
affiché envoie un ensemble de primitives graphiques :
Pour chaque primitive graphique
![]() , on peut déterminer la surface de l'écran
, on peut déterminer la surface de l'écran ![]() qu'elle va remplir en nombre de pixels.
Cette valeur peut être infiniment grande (on ne considère pas le view frustrum culling).
Elle peut être infiniment petite (pour un triangle infiniment petit par exemple).
qu'elle va remplir en nombre de pixels.
Cette valeur peut être infiniment grande (on ne considère pas le view frustrum culling).
Elle peut être infiniment petite (pour un triangle infiniment petit par exemple).
Soit ![]() la taille de triangle considérée comme parfaite (cf. [WW03]).
Cette valeur dépend notamment de l'application visée.
Pour fixer les idées, pour une qualité maximum, on a
la taille de triangle considérée comme parfaite (cf. [WW03]).
Cette valeur dépend notamment de l'application visée.
Pour fixer les idées, pour une qualité maximum, on a
![]() .
.
Pour chaque primitive graphique
![]() , on peut alors exprimer l'aire ``normalisée'' :
, on peut alors exprimer l'aire ``normalisée'' :
![]() .
Cette fonction vaut
.
Cette fonction vaut ![]() lorsque la primitive a la taille idéale.
lorsque la primitive a la taille idéale.
On peut calculer l'aire normalisée moyenne de toutes les primitives graphiques envoyées à la carte graphique par un amplifieur :
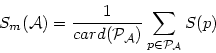
![]() est à valeur dans
est à valeur dans ![]() .
.
Le but de Dynamic Graph est donc de générer des amplifieurs tels que
![]() .
Afin de bien résoudre cette équation, il est préférable de mieux conditionner l'équation en prenant son logarithme :
.
Afin de bien résoudre cette équation, il est préférable de mieux conditionner l'équation en prenant son logarithme :
![]() .
.
La définition théorique de la précision d'un amplifieur est :
Remarquons que lorsque les primitives sont deux fois plus grandes que la taille idéale, on a :
![]()
Lorsqu'elles sont deux fois plus petites, on a :
![]()
En pratique, le calcul précis de la surface de chaque primitive est inutilement coûteux. En effet, l'expérience montre qu'une grossière estimation est largement suffisante pour obtenir des résultats satisfaisants.
Ainsi, le calcul de
![]() est ramené à la formule suivante :
est ramené à la formule suivante :
![]() est la surface projetée d'une boîte englobante sphérique de l'amplifieur.
Comme nous le verrons dans le chapitre suivant, la boîte englobante est spécifiée par le créateur lors de la modélisation.
est la surface projetée d'une boîte englobante sphérique de l'amplifieur.
Comme nous le verrons dans le chapitre suivant, la boîte englobante est spécifiée par le créateur lors de la modélisation.
![]() est un coefficient de calibration qui reflète la discrétisation de l'amplifieur.
Par exemple, un maillage sphérique très échantillonné aura un coefficient
est un coefficient de calibration qui reflète la discrétisation de l'amplifieur.
Par exemple, un maillage sphérique très échantillonné aura un coefficient
![]() inférieur à
inférieur à ![]() .
À l'opposé, un maillage sphérique peu échantillonné aura un coefficient
.
À l'opposé, un maillage sphérique peu échantillonné aura un coefficient
![]() proche de
proche de ![]() .
.
 |
Ces deux coefficients sont donnés par le créateur pour chaque générateur d'amplifieurs (cf. figure 6.15).
C'est donc ce dernier qui spécifie entièrement la fonction de précision.
Par expérience, la gène occasionnée par la détermination d'une boîte englobante sphérique et du coefficient
![]() sont minimes (en tout cas négligeable par rapport au reste du modèle).
sont minimes (en tout cas négligeable par rapport au reste du modèle).
La fonction
![]() est celle utilisée dans le critère d'arrêt de précision de chaque amplifieur
est celle utilisée dans le critère d'arrêt de précision de chaque amplifieur ![]() .
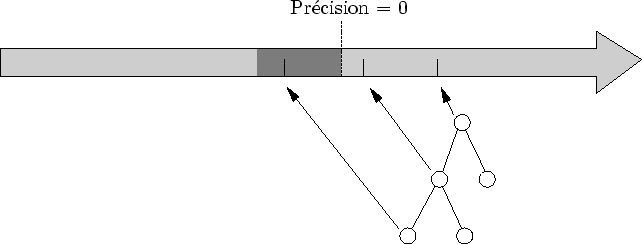
Le test de précision est très simple : si la précision est négative, cela signifie qu'elle est suffisante (cf. figure 6.16).
.
Le test de précision est très simple : si la précision est négative, cela signifie qu'elle est suffisante (cf. figure 6.16).
 |
Remarquons, qu'une simple variation de ![]() permet de diminuer la précision (et donc la qualité) tout en augmentant les performances (moins de géométrie est générée).
Dynamic Graph propose donc un contrôle total sur le coefficient
permet de diminuer la précision (et donc la qualité) tout en augmentant les performances (moins de géométrie est générée).
Dynamic Graph propose donc un contrôle total sur le coefficient
![]() .
.
Des contrôles plus fins sont permis : la valeur de ![]() peut varier par générateur d'amplifieurs.
Ceci permet la calibration relative de modèles d'origine différente lors de leur mise en commun.
peut varier par générateur d'amplifieurs.
Ceci permet la calibration relative de modèles d'origine différente lors de leur mise en commun.
Nous verrons ici comment la précision est transformée en une valeur utilisable par le créateur : la maturité. La maturité est une sorte de normalisation de la précision idéale pour interpoler continûment l'ajout de détail d'un amplifieur. Nous verrons deux versions de la maturité : synchrone et asynchrone.
Le rôle que joue la précision dans les critères d'arrêt est discret : l'amplifieur génère des fils ou non. La nature continue de la précision est utilisée pour assurer le passage continu d'un amplifieur à ses amplifieurs fils. Pour reprendre le vocabulaire utilisé dans le chapitre 4, les transitions entre niveaux de détail doivent être continues.
Dynamic Graph accorde une grande importance à cette continuité. De nombreux critères plus ou moins importants sont garants du ``bon'' déroulement d'une transition. Nous plaçons la continuité parmi les plus importants : le moindre popping visuel détériore très notablement la qualité du rendu.
Soyons clairs, Dynamic Graph n'assure pas automatiquement ces transitions. Il propose simplement au créateur un coefficient d'interpolation qui permettra à ce dernier d'ajouter la précision continûment. Ce coefficient est appelé maturité. Lorsque la maturité est nulle, les détails codés par l'amplifieur sont indiscernables. Lorsque la maturité vaut un, l'amplifieur a ajouté toute la précision dont il était capable.
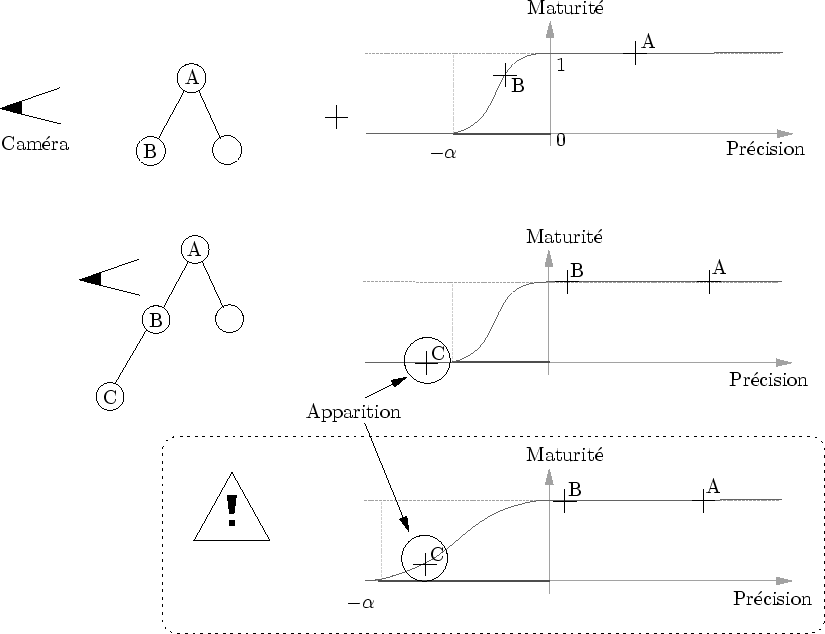
Remarquons qu'il est essentiel que lors de l'apparition d'un amplifieur fils, la maturité de ce dernier soit nulle. Dans le cas contraire, on distinguera un pop de la forme car celle-ci sera subitement enrichie.
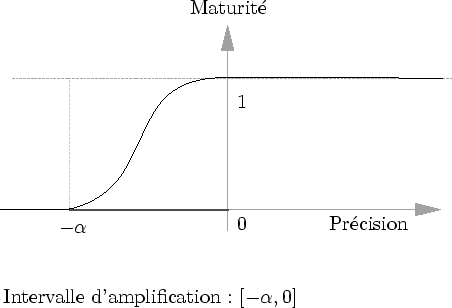 |
La première définition de la maturité qui vient à l'esprit est une simple transformation de la précision
![]() (cf. figure 6.17).
Cette fonction est principalement définie par
(cf. figure 6.17).
Cette fonction est principalement définie par ![]() déterminant la taille de l'intervalle d'amplification.
déterminant la taille de l'intervalle d'amplification.
 |
Cette taille dépend de l'amplifieur et de la précision qu'il couvre.
C'est au créateur de régler le coefficient ![]() (par calibrage expérimental).
Celui-ci doit-être suffisamment petit sans quoi un amplifieur peut apparaître avec une transition non-nulle (cf. figure 6.18).
Ceci entraîne des discontinuités de l'affichage à proscrire absolument.
Dans le cas de la prairie, on aura par exemple la représentation 2.5D qui apparaîtra soudainement sur la représentation 2D sans ``pousser'' continûment.
(par calibrage expérimental).
Celui-ci doit-être suffisamment petit sans quoi un amplifieur peut apparaître avec une transition non-nulle (cf. figure 6.18).
Ceci entraîne des discontinuités de l'affichage à proscrire absolument.
Dans le cas de la prairie, on aura par exemple la représentation 2.5D qui apparaîtra soudainement sur la représentation 2D sans ``pousser'' continûment.
Cette version de la maturité est appelée maturité synchrone car pour une position de la caméra correspond une valeur unique de la maturité pour chaque amplifieur.
Le principal problème lié à cette maturité est qu'elle autorise un amplifieur à rester dans des positions intermédiaires (comme ![]() ). Or, dans certains cas (cf. sous-section 4.1.3), l'esthétique des positions intermédiaires peut être inférieure à celle des positions de repos (
). Or, dans certains cas (cf. sous-section 4.1.3), l'esthétique des positions intermédiaires peut être inférieure à celle des positions de repos (![]() ou
ou ![]() ).
Nous en avons vu un exemple pour les états de transition entre 2D et 2.5D dans le cas de prairie.
Pour remédier à ce problème, Dynamic Graph propose des transitions asynchrones.
).
Nous en avons vu un exemple pour les états de transition entre 2D et 2.5D dans le cas de prairie.
Pour remédier à ce problème, Dynamic Graph propose des transitions asynchrones.
La maturité asynchrone dépend du temps : une fois déclenchée (quelque soit le sens), elle se termine forcément.
Pour cela, il faut définir deux valeurs de précision ![]() et
et ![]() telles que :
telles que :
Le principal problème avec cette technique est que la maturité a de ``l'inertie''. En conséquence, la forme se modifie toujours même lorsque la caméra ne bouge pas. Ceci n'a pas d'importance pour la plupart des objets animés car cela passe inaperçu : l'animation des objets ``cache'' l'animation due à la maturité. En revanche, pour les objets non-animés, cela nuit indéniablement à la qualité de l'effet visuel.
L'astuce ici consiste à faire varier la vitesse ![]() en fonction des mouvements de la caméra (ou tout autre action ``diversive'').
Dès que la caméra bouge ``sensiblement'', la vitesse
en fonction des mouvements de la caméra (ou tout autre action ``diversive'').
Dès que la caméra bouge ``sensiblement'', la vitesse ![]() augmente.
En fait, pour détecter les mouvements de la caméra, on peut utiliser la dérivée de la précision :
augmente.
En fait, pour détecter les mouvements de la caméra, on peut utiliser la dérivée de la précision :
On a alors (en gardant les seuils de déclenchement ![]() et
et ![]() ) :
) :
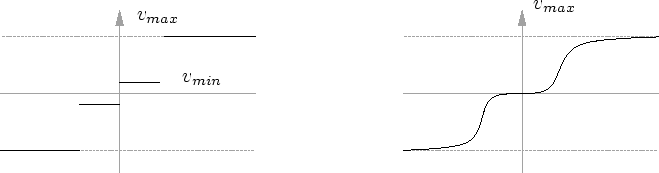 |
La fonction ![]() détermine comment on doit interpréter les variations de la précision (cf. figure 6.19).
Cette méthodet fonctionne mais donnent des résultats médiocres pour certains types d'observation ``brutales''.
Par exemple, si le marcheur court très vite vers la prairie, les niveaux de détails n'auront pas le temps de s'adapter.
Pour éviter ce genre de problème, un mécanisme de détection de discontinuité est mis en place : si la précision varie plus qu'un certain seuil, on revient l'espace d'un pas de temps vers une maturité synchrone.
détermine comment on doit interpréter les variations de la précision (cf. figure 6.19).
Cette méthodet fonctionne mais donnent des résultats médiocres pour certains types d'observation ``brutales''.
Par exemple, si le marcheur court très vite vers la prairie, les niveaux de détails n'auront pas le temps de s'adapter.
Pour éviter ce genre de problème, un mécanisme de détection de discontinuité est mis en place : si la précision varie plus qu'un certain seuil, on revient l'espace d'un pas de temps vers une maturité synchrone.
Nous verrons tout d'abord dans ce bilan comment la maturité pourrait être étendue pour assurer la prise en charge de contraintes plus complexes. Ensuite, nous dresserons un bilan de la précision et conclurons en affichant Dynamic Graph comme un véritable laboratoire perceptuel dédié à la multi-échelle.
Peut être qu'il existe une fonction de maturité valide pour tous les types d'observations. Mais peut-être sommes-nous là aussi victimes de la loi du cas particulier. En fait, il semblerait que chaque générateur d'amplifieurs nécessite une fonction personnalisée qui dépend de la manière dont on l'observe, de son type d'animation.
On peut considérer la maturité comme une variable réactive, c'est-à-dire une variable dont la valeur dépend des valeurs précédentes. Dynamic Graph propose différentes fonctions par défaut que le créateur peut choisir selon le générateur d'amplifieurs modélisé.
Mais surtout, la connaissance des pas de temps précédents permet au créateur d'écrire ses propres variables réactives.
On peut imaginer, par exemple, des amplifieurs dont la maturité doit fuir certaines valeurs ![]() pour lesquelles le résultat n'est graphiquement pas de bonne qualité.
pour lesquelles le résultat n'est graphiquement pas de bonne qualité.
La fonction de maturité pourrait à la limite être conçue comme le résultat d'une ``simulation physique'' complexe dont les forces tendraient à minimiser les désagréments de l'affichage. La connaissance des valeurs au pas de temps précédent font de Dynamic Graph l'outil idéal pour réaliser ce genre de simulation dans un monde procédural généré à la volée.
La précision utilisée dans Dynamic Graph joue parfaitement son rôle : via une simple calibration visuelle pour déterminer un bon
![]() , un critère d'arrêt automatique libère le créateur de tâches fastidieuses.
La maturité met à la disposition de ce dernier un moyen simple de réaliser des interpolations durant l'ajout de détails et peut être configurée de différentes manières (synchrone, asynchrone).
, un critère d'arrêt automatique libère le créateur de tâches fastidieuses.
La maturité met à la disposition de ce dernier un moyen simple de réaliser des interpolations durant l'ajout de détails et peut être configurée de différentes manières (synchrone, asynchrone).
Remarquons aussi que la précision caractérise ici tout l'amplifieur. Pourtant, on peut très bien imaginer un amplifieur complexe au sein duquel la précision varie de manière non-uniforme. Par exemple, un amplifieur peut représenter un terrain multi-résolution, auquel cas sa précision varie entre les parties proches et l'horizon. Plus généralement, Dynamic Graph implique une décomposition hiérarchique des amplifieurs et ne propose aucune facilité pour les structures continues telles qu'un tronc d'arbre (1D), un terrain (2D) ou du brouillard (3D). Nous discuterons de ces limitations dans le chapitre suivant et montrerons comment Dynamic Graph supporte aussi (mais moins bien) ces structures.
Dynamic Graph, dans sa forme actuelle, ne résout pas les nombreux problèmes perceptuels posés par la synthèse d'image et la multi-échelle en particulier. Certes, le travail effectué sur la maturité apporte quelques éléments de réponse et évite notamment les états intermédiaires. Néanmoins, de nombreux critères n'ont pas été pris en compte : la vitesse des objets, leur importances dans la scène, l'influence du frame-rate, l'excentricité... Pour plus de précision sur ces critères, veuillez consulter l'excellent mémoire de thèse réalisé par Martin Reddy : Perceptually Modulated Level of Detail for Virtual Environnments dont certains éléments ont été repris dans le livre Level of Detail for 3D graphics [LRC+02].
J'aimerais présenter ici Dynamic Graph comme un ``laboratoire perceptuel''. En effet, Dynamic Graph offre un champ d'étude perceptuel très complet et offre une très grande souplesse. En dehors du coeur algorithmique (les arbres d'évaluations), la quasi-totalité des fonctionnalités proposées par défaut sont redéfinissables en C++ lors de la création d'un modèle. Les vitesses et les accélérations des objets sont facilement calculables grâce au tampon d'arbres. La sémantique très forte apportée par la modélisation procédurale permet l'utilisation de critère cognitif. Enfin, les possibilités d'animation et les grandes variations d'échelle permettent la création de cadres d'expérimentations très variés.
La visibilité est, avec la précision, un critère d'arrêt essentiel dans la génération de l'arbre d'évaluation de Dynamic Graph. Nous exposerons tout d'abord le contexte scientifique puis un algorithme original de détection d'objet caché. Nous présenterons ensuite l'algorithme puis détaillerons la plus grande difficulté de sa mise en oeuvre : assurer un parallélisme efficace entre la carte graphique et le processeur central. Nous conclurons ensuite en insistant sur le rôle essentiel de la carte graphique dans cet algorithme.
Avant de décrire le contexte scientifique, je justifierai la présence de cette méthode de détection d'occultation dans ce mémoire portant sur la multi-échelle, et non la visibilité. Notamment, nous verrons comment un triple concours de circonstances favorables ``m'a interdit'' de ne pas implémenter cet algorithme. Ensuite, nous comparerons rapidement ce travail à l'existant par l'étude bibliographique [COCSD03]. Nous énumérerons ensuite les différents travaux portants sur la visibilité et la multi-échelle.
La présence de cet algorithme dans cette thèse peut laisser perplexe. En effet, pourquoi parler de visibilité dans un travail sur la multi-échelle? Au premier regard, cela peut paraître tout simplement hors-sujet. Pourtant, la visibilité et la multi-échelle sont toutes deux motivées par un même but : «n'afficher que ce que l'on voit».
Néanmoins, bien que mues par le même désir, les techniques mises en ![]() uvres dans ces deux méthodes sont radicalement différentes.
En fait, l'implémentation de l'algorithme de détection d'occultation de Dynamic Graph est le fruit d'un concours de trois circonstances favorables.
De ce coup de chance est né un algorithme simple et efficace permettant un calcul de visibilité temps-réel sur des scènes complexes et animées.
uvres dans ces deux méthodes sont radicalement différentes.
En fait, l'implémentation de l'algorithme de détection d'occultation de Dynamic Graph est le fruit d'un concours de trois circonstances favorables.
De ce coup de chance est né un algorithme simple et efficace permettant un calcul de visibilité temps-réel sur des scènes complexes et animées.
La première circonstance favorable est le besoin.
La principale raison pour laquelle Dynamic Graph nécessite un algorithme de détection d'occultation est son efficacité.
Sur certaines scènes très complexes (comme le cube de Sirpienski), ![]() des objets dessinés par un algorithme de base n'étaient pas visibles.
des objets dessinés par un algorithme de base n'étaient pas visibles.
La seconde circonstance est l'apparition d'une nouvelle extension sur les nouvelles cartes graphiques : GL_ARB_occlusion_query . Cette extension s'est démocratisée en 2002 et elle est désormais sur toutes les cartes graphiques. Elle permet de compter le nombre de pixels qui atteignent l'écran6.3. L'une des applications immédiates de cette extension est un calcul de détection d'occultation (ou calcul de visibilité) : lorsque le nombre de pixels allumés par un objet vaut zéro, ce dernier n'est pas visible. On peut donc l'ignorer puisqu'il ne contribuera pas à l'image finale.
La troisième circonstance favorable est l'utilisation de la modélisation procédurale multi-échelle. En effet, tout était prêt, dans Dynamic Graph, à accueillir l'algorithme de visibilité décrit plus loin. Les boîtes englobantes hiérarchiques étaient déjà utilisées pour le calcul de précision et le view frustrum culling. L'absence de précalcul, imposée par la modélisation procédurale, montrait presque la solution du doigt... Je ne pouvais pas ne pas implémenter cet algorithme.
Pour un état de l'art exhaustif sur le problème de la visibilité, je vous renvoie à la thèse de Frédo Durand [Dur99]. Plus récemment, une excellente étude bibliographique [COCSD03] recense de très nombreuses méthodes. Surtout, elle propose une taxonomie très précise permettant une rapide et précise description des différents algorithmes de visibilité (section 2 : Classification).
Selon cette taxonomie, voici une description de l'algorithme implémenté dans Dynamic Graph :
[COCSD03] propose d'autres critères descriptifs :
Un dernier critère manque peut-être à l'appel : l'utilisation de méthodes multi-échelles. En effet, certains travaux se démarquent par l'utilisation simultanée d'un algorithme de visibilité et d'une méthode multi-échelle. À notre connaissance, la totalité d'entre eux est basée sur des méthodes de simplification hiérarchique [YSM03,ESSS01,GLY+03,ISGM02,ACW+99]. Les précalculs effectués limitent ou interdisent l'animation. En effet, lorsque le modèle change trop, il faut remettre à jour la hiérarchie.
Dans la catégorie des algorithmes alliant visibilité et multi-échelle, mon travail est le premier utilisant une approche procédurale par complexification. Par conséquent, compte tenu de l'aspect dynamique de cette approche, il est aussi le premier à permettre une animation massive, en ce sens que tous les niveaux de la hiérarchie peuvent être animés.
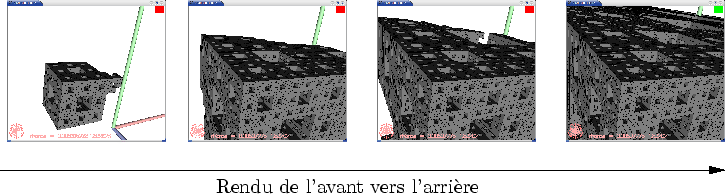
Sont expliquées ici les grandes lignes de cet algorithme de détection de face cachée. Celui-ci est basé sur la fonction GL_ARB_occlusion_query permettant de compter les pixels allumés par la boite englobante de la forme contenu dans un amplifieur. Avec un rendu de l'avant vers l'arrière, il est alors possible de déterminer quel objet est au moins partiellement visible. Ensuite, nous verrons pourquoi et comment limiter le nombre d'appels à la fonction GL_ARB_occlusion_query .
La fonction GL_ARB_occlusion_query n'est en fait qu'un simple compteur de fragments non rejetés (cf. figure 6.20). Le début et la fin du compte sont spécifiés par des commandes OpenGL s'insérant dans le flux d'information qui part vers la carte graphique. Le compteur est situé après le depth test.
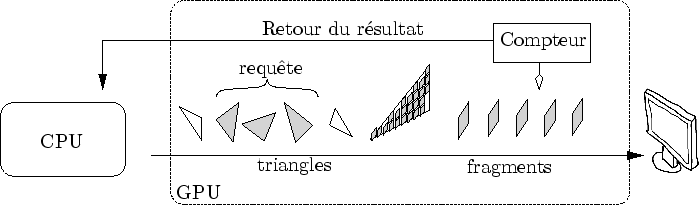 |
Lorsque l'on affiche un objet en l'entourant de commandes de début et de fin de requête6.4, la fonction
GL_ARB_occlusion_query compte le nombre de pixels qui s'allument.
Si l'on prend soin de désactiver l'écriture dans le tampon de couleur et de profondeur, il est possible de réaliser ce test sans influencer l'affichage.
En affichant la boîte englobante d'un objet, on obtient une borne supérieure du nombre de pixels qu'aurait affiché cet objet. L'utilisation de boîtes englobantes entraîne donc une perte de précision, mais aussi un gain de rapidité. En effet, celles-ci sont plus grossières et donc beaucoup plus rapides à afficher que les objets qu'elles englobent. De plus, dans Dynamic Graph, rappelons-le, on ne connaît même pas l'objet que l'on va afficher : celui-ci dépend de la précision.
La fonction GL_ARB_occlusion_query nous donne un moyen de calculer une sur-estimation de la surface réellement affichée de l'objet occulté. Pour avoir un algorithme conservatif, il faut que l'obstacle utilisé soit en quelque sorte une sous-estimation de l'obstacle réel. Dans notre cas, l'obstacle est le Z-buffer. Celui-ci, durant tout son remplissage, est une sous-estimation du Z-buffer final obtenu à la fin de l'affichage.
L'idéal serait de lancer les requêtes de visibilité sur le Z-buffer final. Ceci est malheureusement impossible car on ne peut remplir un Z-buffer qu'en évaluant la scène. Or, le calcul de visibilité est justement nécessaire à l'évaluation de cette scène : le problème ``se mord la queue''. On pourrait imaginer utiliser le Z-buffer au pas de temps précédent. Celui-ci est effectivement souvent une bonne approximation de la valeur courante. Malheureusement, assurer un calcul conservatif dans ces conditions est très difficile6.5.
Afin de permettre un calcul de la visibilité en même temps que le calcul de la scène, celle-ci est rendue de l'avant vers l'arrière grâce à un parcours adéquat (cf. figure 6.21 et 5.9). Le but du jeu est de remplir le Z-buffer aussi vite que possible avec des valeurs aussi proches de la caméra que possible. De cette façon, le Z-buffer sera un occluder de bon qualité (i.e qui cachera le plus de chose possible). Avant d'enrichir un amplifieur, sa boîte englobante sera testée sur le Z-buffer courant (cf. figure 6.22). Les fils ne seront générés que si le nombre de pixels allumés par la boîte englobante n'est pas nul.
 |
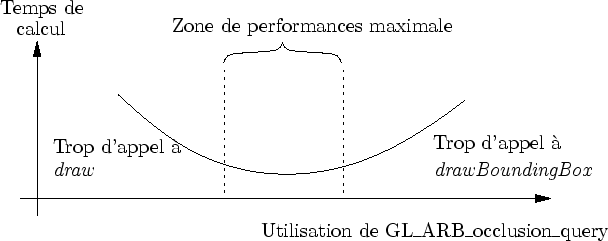
Lors de l'évaluation d'un amplifieur, le générateur peut évaluer les fonctions draw ou drawBoundingBox (ou les deux). Le but de l'organiseur est ici assez complexe : il doit bien sûr minimiser le nombre d'appels à la fonction draw. Pour cela, il va utiliser les fonctions drawBoundingBox qui, via une utilisation de GL_ARB_occlusion_query , détecte si l'amplifieur est occulté.
Mais il doit aussi minimiser le nombre d'appel à la fonction drawBoundingBox, notamment très coûteuse au niveau du taux de remplissage. Le problème ressemble à une minimisation (cf. figure 6.23). Une façon d'aborder ce problème est de donner une valeur de pertinence aux requêtes de visibilité dans le but d'en ignorer certaines. Remarquons que, conservativité oblige, tout requête non pertinente est considérée comme positive : l'objet est par défaut visible.
 |
De nombreux critères déterminent la pertinence d'une requête :
Ces critères sont combinés pour former une heuristique décidant si la requête doit être lancée ou non. Une analyse précise n'a pas été réalisée et très clairement, cette heuristique est très perfectible. Actuellement, une somme pondérée de ces critères, avec des coefficients choisis empiriquement, est comparée à un seuil : le test de visibilité n'est réalisé que si la pertinence est suffisante.
La subtilité majeure de l'algorithme présenté ici est d'assurer une bonne assynchronisation entre la carte graphique et le processeur central. Nous verrons tout d'abord pourquoi une approche naïve nuit fatalement aux performances. Ensuite, nous énumérerons les moyens existants de synchronisation entre le CPU et le GPU. Enfin, nous détaillerons la mise en oeuvre du parallélisme et discuterons des auto-occultations.
L'utilisation de GL_ARB_occlusion_query requiert quelques précautions d'utilisation. En effet, imaginons une utilisation naïve d'une requête de visibilité :
Cette approche est à proscrire. En effet, si l'utilisateur demande le résultat de la requête juste après l'avoir effectuée, il forcera la géométrie de la boîte englobante à traverser tout le pipe-line sans que celui-ci pourrait continuer à se remplir. La carte graphique se videra pendant que le processeur attend sans rien faire. Le temps moyen de traversée de la carte est non négligeable6.6. En conséquence, il n'est pas tolérable de laisser inactif le GPU et le CPU à chaque requête de visibilité.
Si l'on compare le CPU avec un énorme carrefour complexe et très fréquenté, le GPU est une autoroute à sens unique. Suivant cette métaphore, l'utilisation naïve décrite plus haut revient à laisser entrer quelques voitures sur l'autoroute, puis à la fermer et à attendre que les voitures arrivent à destination avant de la rouvrir. L'accumulation de voitures à l'entrée de l'autoroute paralyserait complètement le grand échangeur (le CPU), contraint d'attendre sans bouger que l'autoroute soit de nouveau ouverte.
Il existe actuellement trois moyens pour contrôler la synchronisation entre un CPU et la carte graphique :
L'utilisation de glFinish est à proscrire (le CPU et le GPU attendent).
L'utilisation des
GL_NV_fence est prometteuse mais n'a pas été étudiée ici.
La solution choisie consiste à utiliser glFlush couplé à une estimation du temps de traversée du GPU.
Pour remédier au temps perdu par une utilisation naïve, il convient avant tout de toujours envoyer de nouvelles informations au GPU. Pour cela, il est absolument nécessaire de ne pas demander le résultat de la requête de visibilité juste après l'avoir exécuté par un glFlush. Chaque amplifieur en attente devient alors bloquant, c'est-à-dire que le générateur ne peut plus les visiter avant que le résultat des requêtes soient disponibles. Si éventuellement tous les noeuds sont bloquants, alors la seule solution est d'attendre que les réponses des requêtes soient disponibles.
De plus, il n'est pas conseillé d'appeler glFlush trop souvent car le bus aime bien les gros paquets d'informations. Il faut donc envoyer des groupes de requêtes. La taille des groupes ne doit pas être trop grande, sans quoi tous les noeuds risquent de devenir bloquants. Cette situation arrive parfois en début de création de graphe lorsque les choix sont peu nombreux. C'est une raison de plus pour développer les tous premiers niveaux du graphe sans tester la visibilité.
Dans Dynamic Graph, le CPU utilise le générateur pour visiter les noeuds non bloquants pendant que le GPU calcule les requêtes de visibilité. Les réponses, une fois rapatriées sur le CPU, vont débloquer les noeuds bloquants et le générateur pourra alors les visiter.
Mais le problème ne s'arrête pas là. Il est nécessaire de limiter les auto-occultations au sein d'un même groupe de requêtes. Afin d'illustrer cette nécessité, penchons nous sur l'exemple suivant : le visiteur laisse les noeuds A et B en attente le temps que leur calcul de visibilité se termine. Pendant ce calcul, A et B n'influent pas sur le Z-buffer (grâce à glDepthMask) mais comptent juste le nombre de pixels qu'allument leurs bounding-box. Que se passe-t-il si A occulte complètement B? Comme les visibilités de A et B sont évaluées en même temps, cette occultation ne sera pas détectée, amenant des calculs inutiles (mais conservativement sans risque).
Il est donc nécessaire de bien répartir les membres d'un groupe de requêtes de visibilité selon leur placement sur l'écran. Idéalement, si les membres sont mutuellement non-recouvrants, le test de visibilité sera optimal. En pratique, il serait trop coûteux d'assurer cette condition et il est suffisant de bien répartir les requêtes sur l'écran pour obtenir de bonne performance. Cette répartition est actuellement implicitement et partiellement réalisé par le tri en profondeur. Cette méthode simpliste devrait pouvoir être améliorer par une meilleur connaissance de la répartition des boîtes englobantes sur le plan de l'image.
Nous décrirons tout d'abord les répercussions importantes de cet algorithme sur l'architecture de Dynamic Graph. D'un point de vue plus abstrait, nous décrirons la carte graphique comme l'observateur du monde virtuel contenu dans les modèles de Dynamic Graph. Plus concrètement, nous discuterons rapidement des performances. Enfin, nous ajouterons une note sur l'utilisation de la transparence avec cet algorithme de visibilité.
Au bout du compte, les contraintes qu'entraîne le parallélisme entre le processeur central et la carte graphique compliquent notablement le pipe-line d'évaluation. Sans rentrer dans les détails, la figure 6.24 donne un aperçu simplifié de la structure utilisée. Le rôle de la salle d'attente est essentiel : elle permet aux amplifieurs d'attendre sagement que leur requête de visibilité soit terminée.
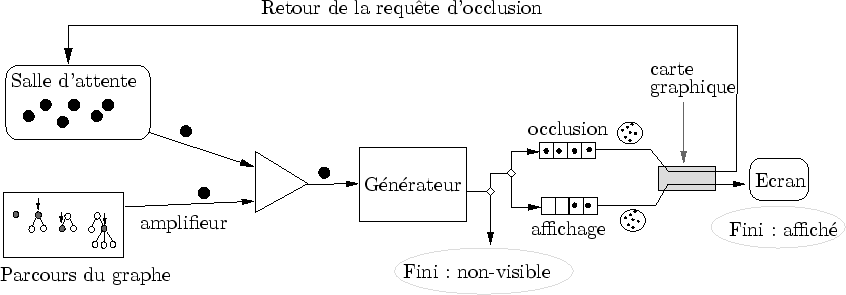 |
Fondamentalement, l'algorithme de rendu de Dynamic Graph est l'esclave de la carte graphique (cf. figure 6.25). Ceci diffère radicalement des approches pour lesquelles on envoie toutes les informations d'un bloc. Ici, l'algorithme de détection d'occultation amène un échange plus complexe.
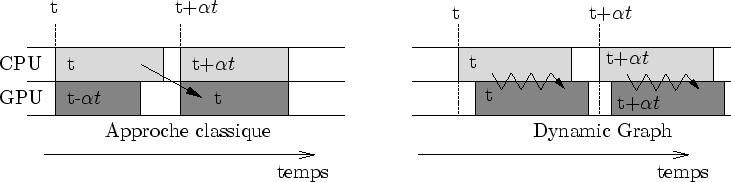 |
Cette évolution est en fait très naturelle.
Rappelons que c'est l'observateur qui limite la génération de l'arbre d'évaluation par des critères de visibilité et de précision.
Ne pourrait on pas considérer que la carte graphique est cet observateur ?
C'est en quelque sorte elle qui observe les données virtuelles du modèle.
On peut représenter la carte graphique comme un ![]() il intermédiaire (dont l'écran est la rétine) entre le modèle et le créateur.
Il est tout naturel que Dynamic Graph interroge la carte graphique pour lui demander son avis : "vous en voulez encore ou on s'arrête là?".
D'ailleurs, il est probable que le calcul de précision ou de view frutrum culling bénéficie aussi un jour des avantages de l'accélération matérielle par un retour de l'information du GPU vers le CPU.
il intermédiaire (dont l'écran est la rétine) entre le modèle et le créateur.
Il est tout naturel que Dynamic Graph interroge la carte graphique pour lui demander son avis : "vous en voulez encore ou on s'arrête là?".
D'ailleurs, il est probable que le calcul de précision ou de view frutrum culling bénéficie aussi un jour des avantages de l'accélération matérielle par un retour de l'information du GPU vers le CPU.
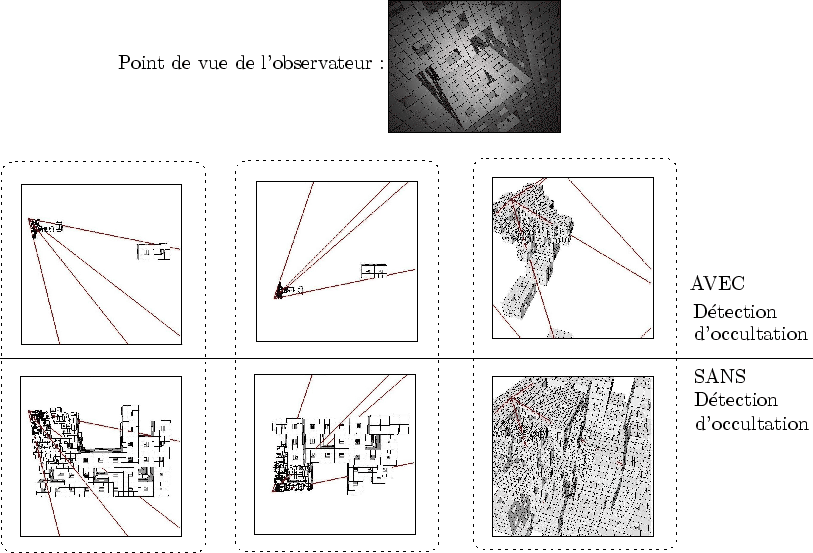
Les résultats sont graphiquement corrects, ce qui est tout à fait normal puisque l'algorithme est conservatif. La figure 6.26 donne un aperçu des résultats grâce à une seconde caméra.
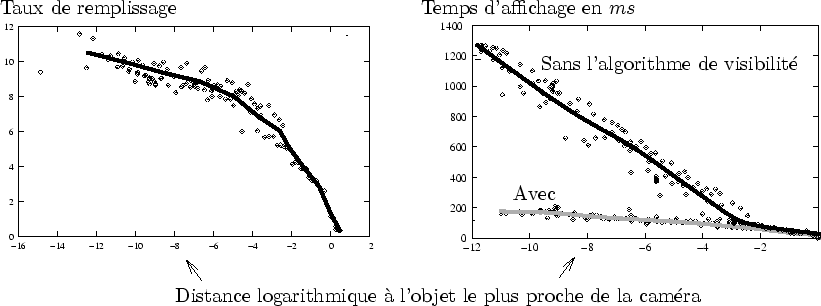
Dans le cas du cube de Sirpienski, une mesure du taux de remplissage a été effectuée (cf. figure 6.27).
Le taux de remplissage mesure le nombre de fragments passant nécessaire au rendu final.
Dans un cas idéal, un seul fragment serait envoyé par pixel.
Mais ce chiffre n'est jamais égalé notamment parce qu'un grand nombre de fragments inutils doit être produit pour obtenir le résultat final.
Au final, on peut mesurer le nombre total de fragments générés en équivalent écrans.
Par exemple, un taux de remplissage égal à
![]() signifie que l'équivalent de
signifie que l'équivalent de ![]() écrans a été rempli par les fragments durant un affichage.
écrans a été rempli par les fragments durant un affichage.
Le taux de remplissage engendré par l'affichage lui-même est très stable et reste entre
![]() et
et
![]() (cette valeur dépend beaucoup du modèle).
Lorsque la caméra est très proche du cube, le taux de remplissage engendré par les boîtes englobantes monte jusqu'à
(cette valeur dépend beaucoup du modèle).
Lorsque la caméra est très proche du cube, le taux de remplissage engendré par les boîtes englobantes monte jusqu'à
![]() .
Au total, le taux de remplissage est monté jusqu'à
.
Au total, le taux de remplissage est monté jusqu'à
![]() pour une observation très proche.
Sans l'algorithme de détection d'occultation, dans les même conditions, le taux de remplissage vaut
pour une observation très proche.
Sans l'algorithme de détection d'occultation, dans les même conditions, le taux de remplissage vaut
![]() (soit un facteur
(soit un facteur ![]() ) !!
Clairement, le jeu en vaut la chandelle.
) !!
Clairement, le jeu en vaut la chandelle.
Néanmoins, un taux de remplissage de ![]() peut être jugé trop élevé.
Nous estimons que les heuristiques utilisées pour décider de l'exécution ou non du test de détection d'occultation sont actuellement très basiques.
Une étude plus poussée améliorerait sans aucun doute ces résultats.
peut être jugé trop élevé.
Nous estimons que les heuristiques utilisées pour décider de l'exécution ou non du test de détection d'occultation sont actuellement très basiques.
Une étude plus poussée améliorerait sans aucun doute ces résultats.
Le plus surprenant vient du fait que, d'une part, ce taux de remplissage énorme ne nuit pas à un affichage interactif. Ceci est certainement dû au fait que l'affichage des boîtes englobantes et très élémentaire (aucun éclairage, géométrie grossière). Il est possible que des techniques de early Z test (cf. [WW03]) accélèrent très sensiblement les calculs. De plus, il est clair que la puissance des cartes graphiques actuelles joue un rôle décisif.
Les performances de cet algorithme dépendent du type de scène affiché. Actuellement, seul une dizaine de modèles relativement simples ont été réalisés. Pour chacun d'eux, le gain est évident. Il est difficile de prédire les résultats dans le cas général. Il est pourtant clair que plus le taux de remplissage de la scène est grand, plus les performances seront bonnes. Par conséquent, plus la scène est complexe et volumique, plus le gain sera marqué. Quant à la comparaison de cet algorithme avec les algorithmes existants, le constat est simple : plus la scène affichée sera vaste, précise, chaotique et animée, plus l'algorithme présenté ici montrera sa supériorité.
 |
La transparence n'est actuellement pas permise en même temps que l'utilisation de l'algorithme de visibilité.
Cela est dû au fait qu'il est actuellement impossible de mettre à jour le Z-buffer en utilisant la fonction glBlendFunc avec un rendu de l'avant vers l'arrière.
Suite à une discussion avec Fabrice Neyret, il semblerait qu'une extension très simple puisse remédier à ce problème.
Il suffirait d'ajouter une nouvelle sorte de test ![]() du type :
du type :
si (![]() >
>
![]() )
alors
)
alors
![]()
La valeur
![]() détermine la valeur à partir de laquelle on considère le pixel comme opaque.
Cette extension est simple et prometteuse mais reste à être implémenter en hardware.
détermine la valeur à partir de laquelle on considère le pixel comme opaque.
Cette extension est simple et prometteuse mais reste à être implémenter en hardware.
Les entrailles de la bête sont désormais connues, voyons comment on peut la dompter.
Dynamic Graph offre une structure très dynamique régénérée à chaque pas de temps. Néanmoins, contrairement à la plupart des méthodes procédurales ``à la volée'', des mécanismes permettent d'accéder aux valeurs des pas de temps précédent.
La forme affichée est une fonction de l'observateur, en perpétuelle adaptation aux variations de ce dernier. Des critères de précision et de visibilité assurent que seule l'information nécessaire à l'observation est générée.
La structure en pipe-line de la carte graphique influe notablement l'architecture de Dynamic Graph. Des méthodes de parallélisme dédiées permettent au processeur central d'utiliser la puissance de ces dernières sans pour autant nuire aux performances.
Il peut paraître un peu ambitieux de proposer une solution recouvrant tout le processus de création. Généralement, un travail de recherche est plus local et s'attarde exclusivement sur la modélisation ou l'animation ou le rendu, mais pas sur tous ces domaines à la fois !
Tout d'abord, précisons que le processus de création que j'ai développé dans Dynamic Graph est très simpliste. Notamment, comme nous le verrons bientôt, la phase de modélisation est réalisée essentiellement par une interface textuelle. J'aimerais préciser aussi que j'aurais aimer me raccrocher à des outils existants. Mais l'originalité du langage descriptif de Dynamic Graph impose, en amont et en aval du processus de création, des outils très spécifiques. Nous venons de voir les particularités de l'algorithme de rendu (en aval). Voyons maintenant les particularités de l'algorithme de modélisation (en amont).
Dynamic Graph propose une représentation plus fondamentale dans laquelle l'affichage ne joue finalement qu'un second rôle. La modélisation revient essentiellement à décrire le modèle de façon minimaliste par des paramètres pertinents : plutôt que la surface, c'est le ``squelette'' qui est décrit. Le créateur manipule ensuite ces paramètres pour les animer ou les rendre plus précis.
Voyons maintenant, dans le chapitre suivant, comment aborder cette modélisation complexe.